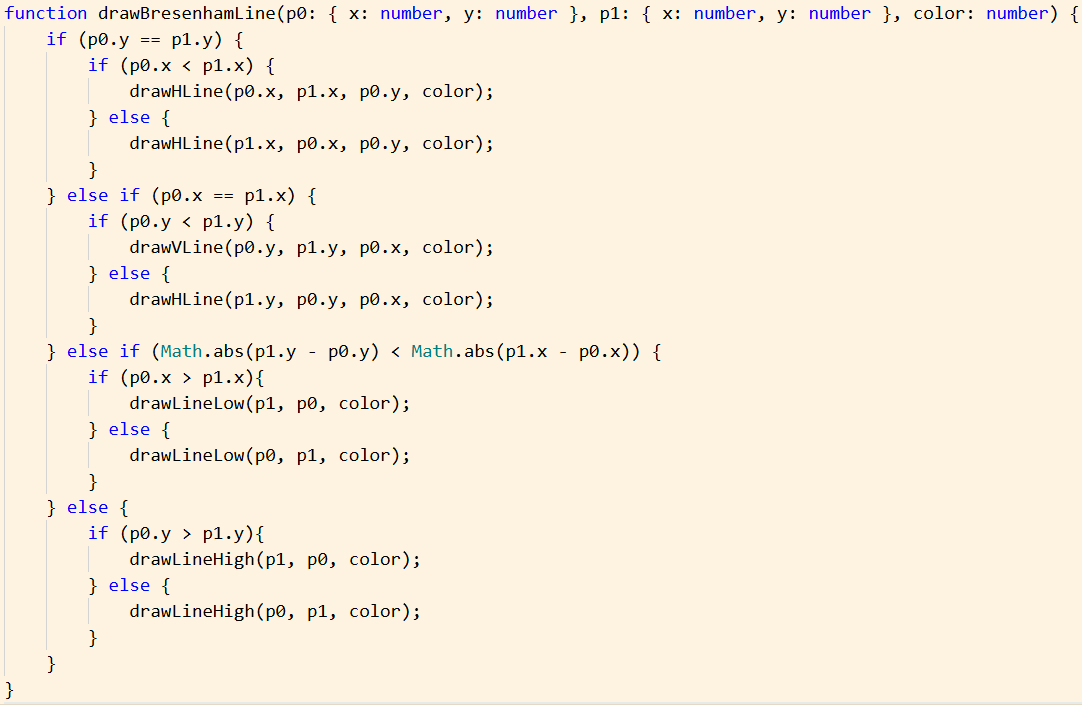
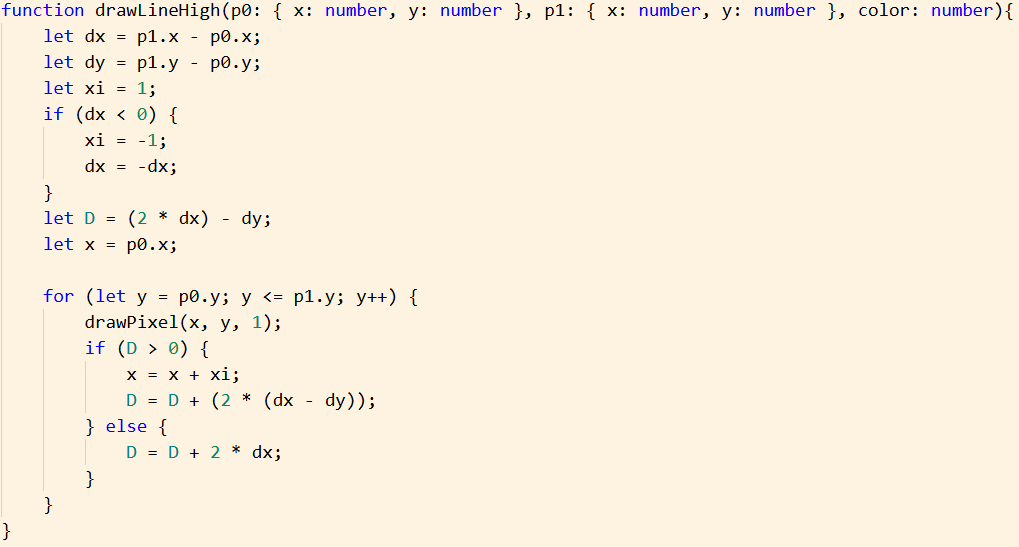
Hello, new to the forums but I’m a middle/highschool comp sci teacher who likes to push the limits of my teaching tools.
I plan to make a 3D renderer from scratch in Makecode Arcade. I know this has been done before in many forms, but I wanted to make sure I was handling this in the most efficient way from the ground up.
That being said… what is the most efficient way to draw a pixel to the screen in Makecode Arcade? I’ve done this in p5.js before by writing data to an image’s pixel array, which to my understanding is the fastest way with that library, but I wanted to ask the wizards here if they had any idea what works best in Arcade.
A couple things I’ve found with preliminary research:
- The image data type lets you create an image from a string. This can then presumably be rendered to the screen at a desired position. I could write a function that sets characters at specific points in the string similar to how I would set the rbga values of a color on a p5.js image.
- Similarly, I can technically set a specific pixel with the setPixel function, though I imagine this might be slightly slower than directly modifying image data myself.
- There are a few other setPixel implementations using onShade and createRenderable
- I’ve found a couple people mentioning Screen.blitRow, though since this wasn’t the most efficient way to draw to the screen in p5.js, I have a suspicion that may be the case here.
And that covers everything I’ve personally found in a few hours of research. Performance is really important for me. I want to create my own implementations of drawing lines and triangles because I’d eventually like to be able to make custom fill options to handle lighting and shading on the fly (by filling triangles with dithered gradients based on normal direction and scene lighting), and potentially eventually do vertex colors or textures. Most other 3D Makecode Arcade projects that I’ve found are using techniques that other threads have stated is suboptimal (one of the devs mentions drawing to scene.backgroundImage is not performant in one of the posts linked above, which is what many current implementations do).
Any thoughts?